
Nature: AI医生MIRA首次“全流程上岗”
Nature: AI医生MIRA首次“全流程上岗”2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。
来自主题: AI技术研报
9024 点击 2026-06-29 10:20
 搜索
搜索
2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。
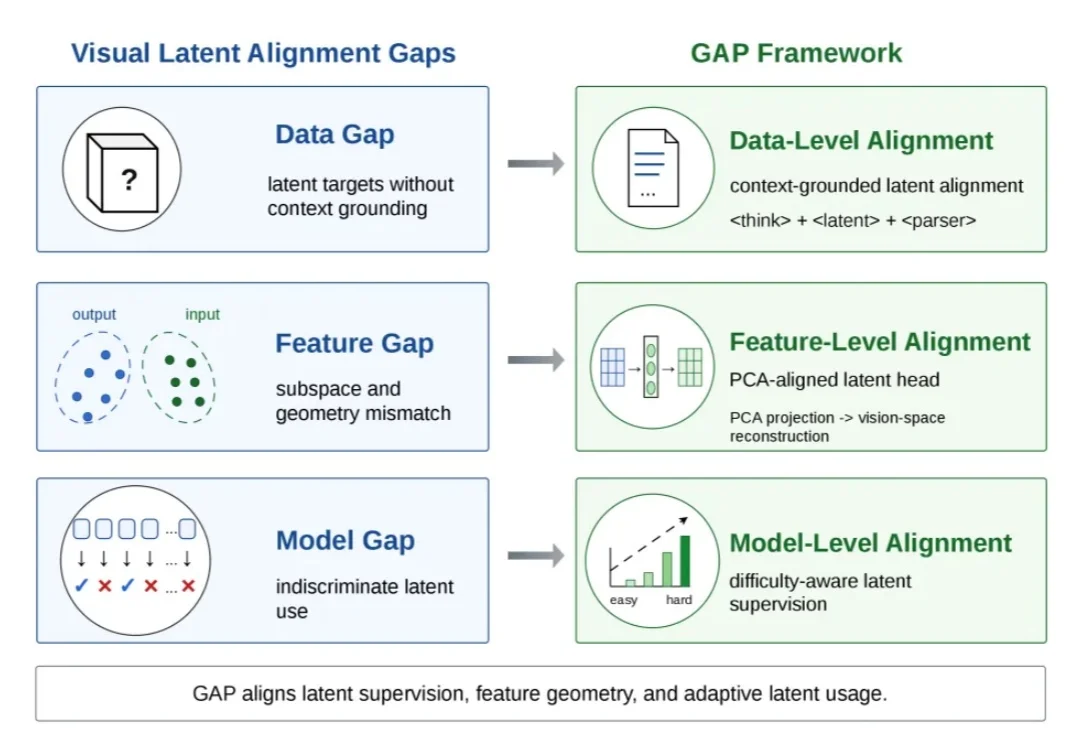
导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。
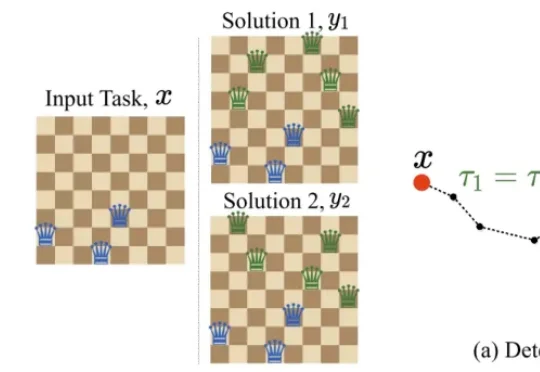
现在,图灵奖得主 Yoshua Bengio 给出了一份全新的并行方案。他们提出了 GRAM(Generative Recursive reAsoning Models,生成式递归推理模型),把确定性的递归潜在推理变成了概率性的多轨迹计算。模型在潜在空间中进行随机递归推理,每一步都可以采样不同的方向,最终形成对解空间的多路径探索。
今天,蚂蚁百灵开源旗舰级思考模型Ring-2.6-1T,该模型于5月9日发布,引入了可调节的Reasoning Effort机制,支持high与xhigh两种推理强度,开发者可以根据任务特性动态分配推理资源。
今天,蚂蚁百灵大模型发布Ring-2.6-1T。这是一款面向真实复杂任务场景的万亿级思考模型,目前已上线OpenRouter,并开放限时一周免费体验,后续将正式开源。Ring-2.6-1T加入了可调节的Reasoning Effort机制。开发者可以在high和xhigh两种推理强度之间选择:high面向Agent、Coding、多步工具调用等高频任务
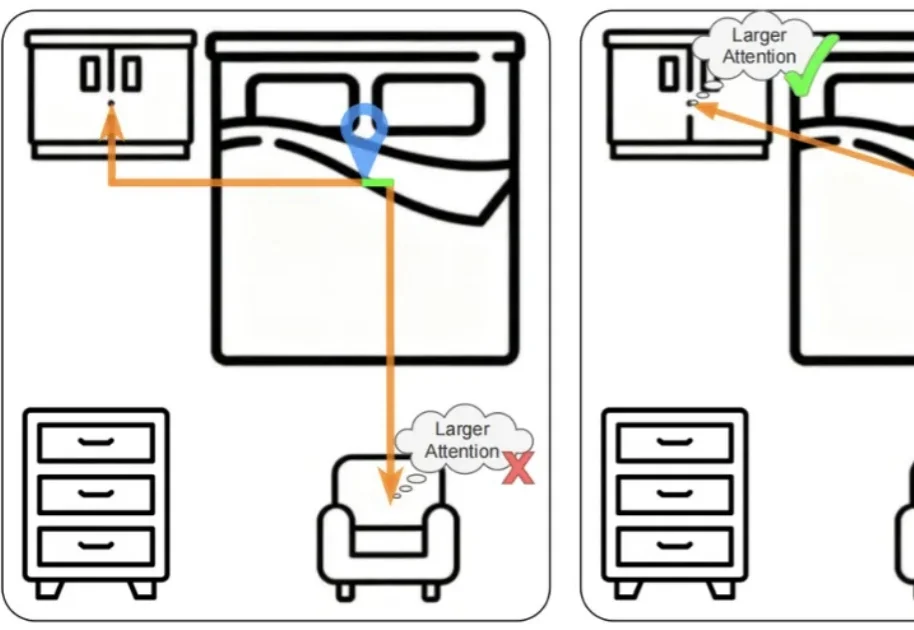
本文主要介绍来自该团队的最新论文:Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models。

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从

简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!